How do you show a vertical or horizontal line on a line
chart in SSRS? After hours or research it seems that approach involving
StripLines works the best.
Horizontal or vertical likes can be used on the chart to
indicate baselines or highlight particular sections as on the sample below:
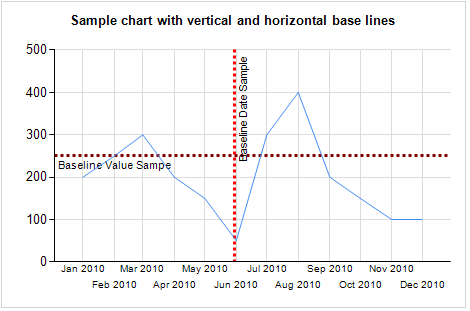
So, how do you build a chart like that? Start with the
data set.
My sample dataset contains a simple query that returns: month
(as date) for X axis, value for Y axis, baseline value for Y axis, baseline
value for X axis (date). In order to properly plot the vertical baseline the date used as a baseline value for X axis must be converted to its integer
representation.
Here is the query:
Declare @table Table (id int identity(1,1), event_date datetime, event_value int)
Insert @table
Select 'Jan 1, 2010', 200
Union Select 'Feb 1, 2010', 250
Union Select 'Mar 1, 2010', 300
Union Select 'Apr 1, 2010', 200
Union Select 'May 1, 2010', 150
Union Select 'Jun 1, 2010', 50
Union Select 'Jul 1, 2010', 300
Union Select 'Aug 1, 2010', 400
Union Select 'Sep 1, 2010', 200
Union Select 'Oct 1, 2010', 150
Union Select 'Nov 1, 2010', 100
Union Select 'Dec 1, 2010', 100
Declare @baseline_value int,
@baseline_date datetime
Set @baseline_value = 250
Set @baseline_date = 'June 1, 2010'
Select
event_date,
event_value,
@baseline_value as baseline_value,
@baseline_date as baseline_date,
CAST(@baseline_date as int) as baseline_date_int
From
@table
The result of the query looks like this:

Create a new report and use above query as a data source. Add new Line Chart object, associate it with the data
source. Select “event_value” column to be used for Values and “event_date”
column will be used for Category Groups.
Modify Horizontal Axis properties as highlighted below:

Format axis label as "MMM yyyy".
Click on X axis and in the properties window find "StipLines" attribute. Click on "Collection" to open collection editor.
Modify attributes as highlighted below:

IntervalOffset value is set using formula "=CInt(Max(Fields!baseline_date_int.Value))".
Do the same steps for Y axis. IntervalOffset value is set using formula "=CInt(Max(Fields!baseline_value.Value))"
Preview the report and enjoy the result!
You can use the same technique to highlight areas on X or Y axis as below. Click here to download sample "Vertical and Horizontal Lines on line graph.rdl" for more details.


